《Python神经网络编程》这本书属于入门读物,小白到连微积分的基础你都不需要有就可以对神经网络有个大概的了解,推荐!我花了几个小时看完了这本书电子版的第一部分(共三部分),然后取消了在当当上这本书的订单 ︿( ̄︶ ̄)︿ 。
第二、三部分主要通过 Python 实现了一个简单的神经网络,用来来识别数字,训练集和测试集为标准的 MNIST 数据库,实测经过3分钟的训练后(样本数为60000个),识别准确率达到了97%。
神经网络如何工作
现代神经网络是一种非线性统计性数据建模工具,是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构和功能的数学模型或计算模型,由大量的人工神经元联结进行计算。典型的神经网络具有以下三个部分:
- 结构(Architecture):结构指定了网络中的变量和它们的拓扑关系。
- 激励函数(Activity Rule):大部分神经网络模型具有一个短时间尺度的动力学规则,来定义神经元如何根据其他神经元的活动来改变自己的激励值。一般激励函数依赖于网络中的权重(即该网络的参数)。
- 学习规则(Learning Rule):学习规则指定了网络中的权重如何随着时间推进而调整。这一般被看做是一种长时间尺度的动力学规则。
训练简单的分类器
简单机器接受了一个输入,并做出应有的预测,输出结果,所以我们将其称为预测器。
使用朴素的调整方法会出现一个问题,即改进后的模型只与最后一次训练样本最匹 配,“有效地”忽略了所有以前的训练样本。解决这个问题的一种好方法是使用学习率,调 节改进速率,这样单一的训练样本就不能主导整个学习过程。
如果数据本身不是由单一线性过程支配,那么一个简单的线性分类器不能对数据进行划 分。例如,由逻辑XOR运算符支配的数据说明了这一点。 但是解决方案很容易,你只需要使用多个线性分类器来划分由单一直线无法分离的数据。
神经元:大自然的计算机器
观察表明,神经元不会立即反应,而是会抑制输入,直到输入增强, 强大到可以触发输出,在数学上可以用阶跃函数 或 S形函数(sigmoid function)来描述这种激活现象。
s函数定义为: y = 1 / (1 + e^(-x))
可以看出激活函数也就是映射。而激活函数的作用是给神经网络加入非线性的因素。激活函数一般都是非线性函数,要是没有了激活函数,那么神经网络难以对于生活中常见的非线性的数据建模。所以,神经网络中激活函数是不可缺少的。
随着神经网络学习过程 的进行,神经网络通过调整优化网络内部的链接权重改进输出,一些权重 可能会变为零或接近于零。零或几乎为零的权重意味着这些链接对网络的 贡献为零,因为没有传递信号。零权重意味着信号乘以零,结果得到零, 因此这个链接实际上是被断开了。
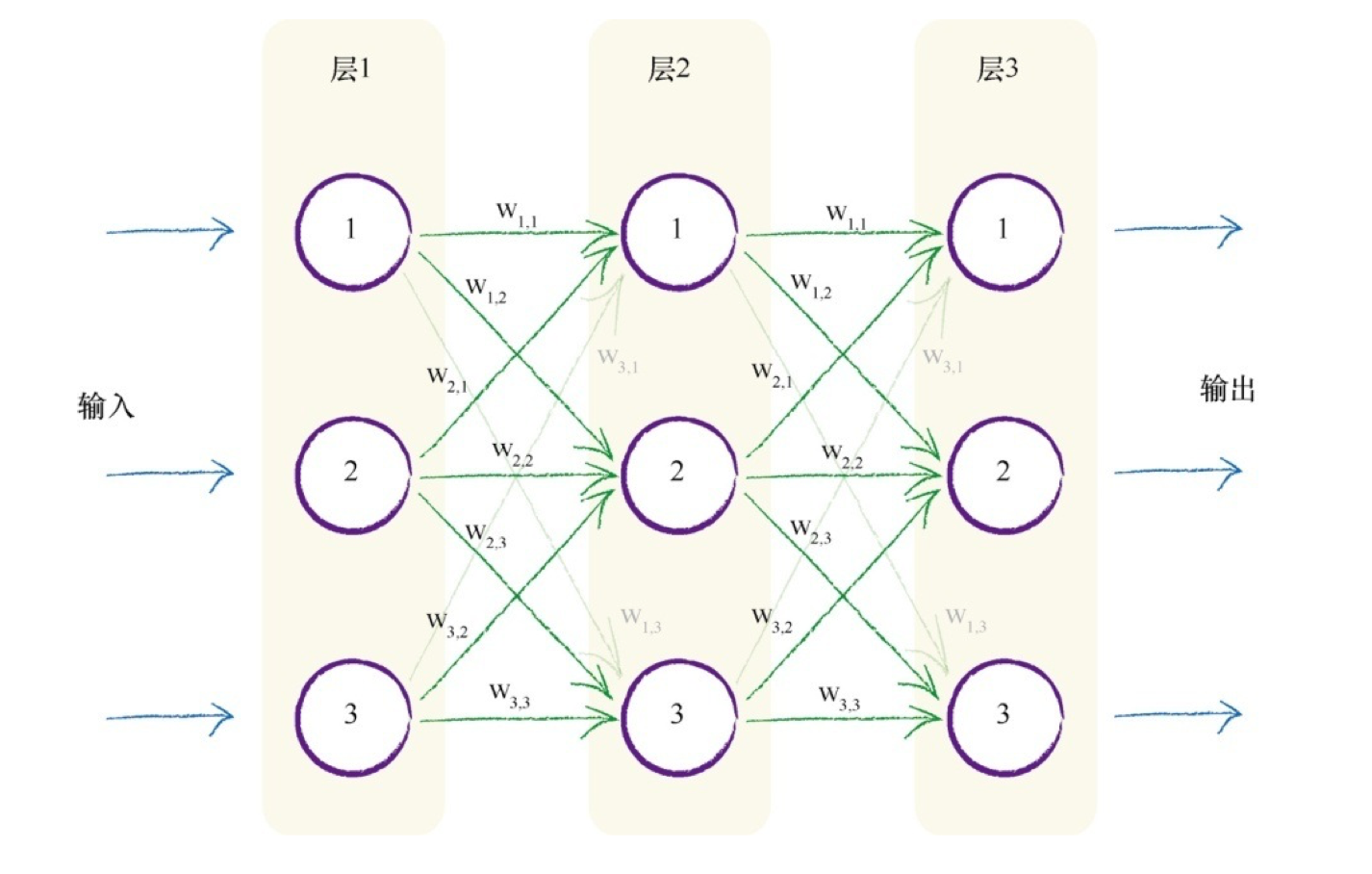
每层神经网络的数学理解:用线性变换跟随着非线性变化,将输入空间投向另一个空间。
通过神经网络向前馈送信号所需的大量运算可以表示为矩阵乘法。不管神经网络的规模如何,将输入输出表达为矩阵乘法,使得我们可以更简洁地进行书写。
反向传播误差
神经网络通过调整链接权重进行学习。这种方法由误差引导,误差就是训练数据所给出正确答案和实际输出之间的差值。误差从输出向后传播到网络中,我们称这种方法为反向传播。
反向传播的意义在于:让误差反向传播到网络的每一层,误差被用来指导如何调整链接权重,从而改进神经网络输出的总体答案。
如何更新权重
神经网络的输出是一个极其复杂困难的函数,这个函数具有许多参数 影响到其输出的链接权重。我们可以使用梯度下降法,计算出正确的权重。
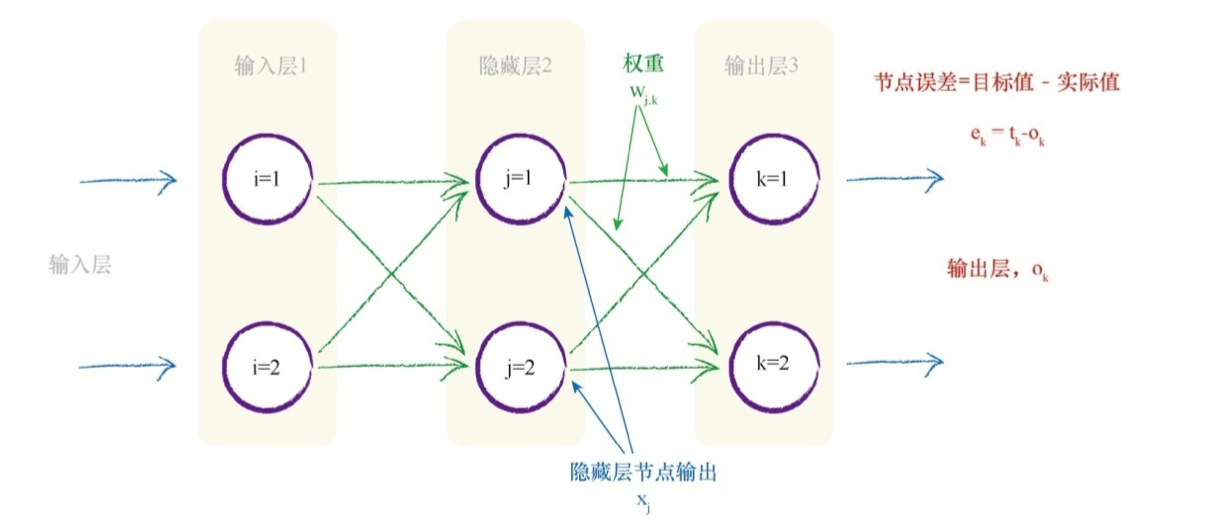
三层网络(上图)权重更新矩阵:
权重改变矩阵中的值可以调整链接权重 Wjk,这个权重链接了当前层节点 j 与下一层节点 k 。你可以发现,表达式中的第一项使用下一层(节点 k )的值,最后一项使用前一层(节点 j )的值。
选择输入、输出和权重
如果输入、输出和初始权重数据的准备与网络设计和实际求解的问题不匹配,那么神经网络并不能很好地工作。
输入
输入应该使得激活函数就会变得看上去比较“陡峭“,即大梯度。因为权重的改变取决于激活函数的梯度。小梯度意味着限制神经网络学习的能力。这就是所谓的饱和神经网络。对于本书中使用的神经网络,因为使用的是 S 激活函数,因此我们应该尽量保持小的输入。
我们也不应该让输入信号太小。当计算机处理非常小或非常大的数字时,可能会丧失 精度,因此,使用非常小的值也会出现问题。一个好的建议是重新调整输入值,将其范围控制在0.0到1.0。
输出
神经网络的输出是最后一层节点弹出的信号,那么尝试将训练目标值设置为比较大的值就有点愚蠢了。如果我们将目标值设置在这些不可能达到的范围,训练网络将会驱使更大的权重,以获得越来越大的输出,而这些输出实际上是不可能由激活 函数生成的。
初始权重
大的初始权重会造成大的信号传递给激活函数,导致网络饱和,从而降低网络 学习到更好的权重的能力,因此应该避免大的初始权重值。
另一个问题是零值信号或零值权重。这也可以使网络丧失学习更好权重的能力。 内部链接的权重应该是随机的,值较小,但要避免零值。如果节点的传入链接较多,有一 些人会使用相对复杂的规则,如减小这些权重的大小。
数学家所得到的 经验规则是,我们可以在一个节点传入链接数量平方根倒数的大致范围内 随机采样,初始化权重。因此,如果每个节点具有3条传入链接,那么初始 权重的范围应该在从 -1/sqrt(3) ~ 1/sqrt(3),即 ±0.577之间。
使用 Python 进行 DIY
使用Python制作神经网络
初始化函数——设定输入层节点、隐藏层节点和输出层节点的数量。
训练——学习给定训练集样本后,优化权重。
查询——给定输入,从输出节点给出答案。
训练网络
训练任务分为两个部分:
- 第一部分,针对给定的训练样本计算输出。
- 第二部分,将计算得到的输出与所需输出对比,使用差值来指导网络 权重的更新。
对于在隐蔽层和最终层之间的权重,我们使用 output_errors(训练样本所提供的预期目标输出值与 实际计算得到的输出值之差,矩阵对应元素相减)进行优化。对于输入层和隐藏层之间的权重,我们使用刚才计算得到的 hidden_errors 进行 优化,hidden_errors 可以通过下面的公式计算得到。
手写数字的数据集 MNIST
手写数字数据库 MNIST:http://yann.lecun.com/exdb/mnist/
简易版本:http://pjreddie.com/projects/mnist-in-csv/
MINST 中的每一行记录组成如下:第一个值是标签,即书写者实际希望表示的数字,如“7”或“9”。这是 我们希望神经网络学习得到的正确答案。随后的值,由逗号分隔,是手写体数字的像素值。像素数组的尺寸是 28 乘以28,因此在标签后有784个值。
使用三层网络进行训练识别数字:
- 输入层:784个节点,这是28×28的结果,即组成手 写数字图像的像素个数。
- 隐藏层:100个节点。这并不是通过使用科学的方法得到的。我们认为,神经网络应该可以发现在输入中的特征或模式,这些模式或特征可以使用比输入本身更简短的形式表达,因此没有选择比784大的数字。通过选择使用比输入节点的数量小的值,强制网络尝试总结输入的主要特点。但是,如果选择太少的隐藏层节点,那么就限制了网络的能力,使网络难以找到足够的特征或模式,也就会剥夺神经网络表达其对MNIST数据理解的能力。
- 输出层:10个节点,因为我们需要10个标签来表征哪一个数字被识别。
改进神经网络
调整学习率
调整这个神经网络中的学习率意味着改变梯度下降过程的速度,因此步长太大或太小都会有问题。
多次运行
就像调整学习率一样,让我们使用几个不同的世代进行实验并绘图, 以可视化这些效果。直觉告诉我们,所做的训练越多,所得到的性能越好。有人可能会注意到,太多的训练实际上会过犹不及,这是由于网络过度拟合训练数据,因此网络在先前没有见到过的新数据上表现不佳。不仅是神经网络,在各种类型的机器学习中,这种过度拟合也是需要注意的。
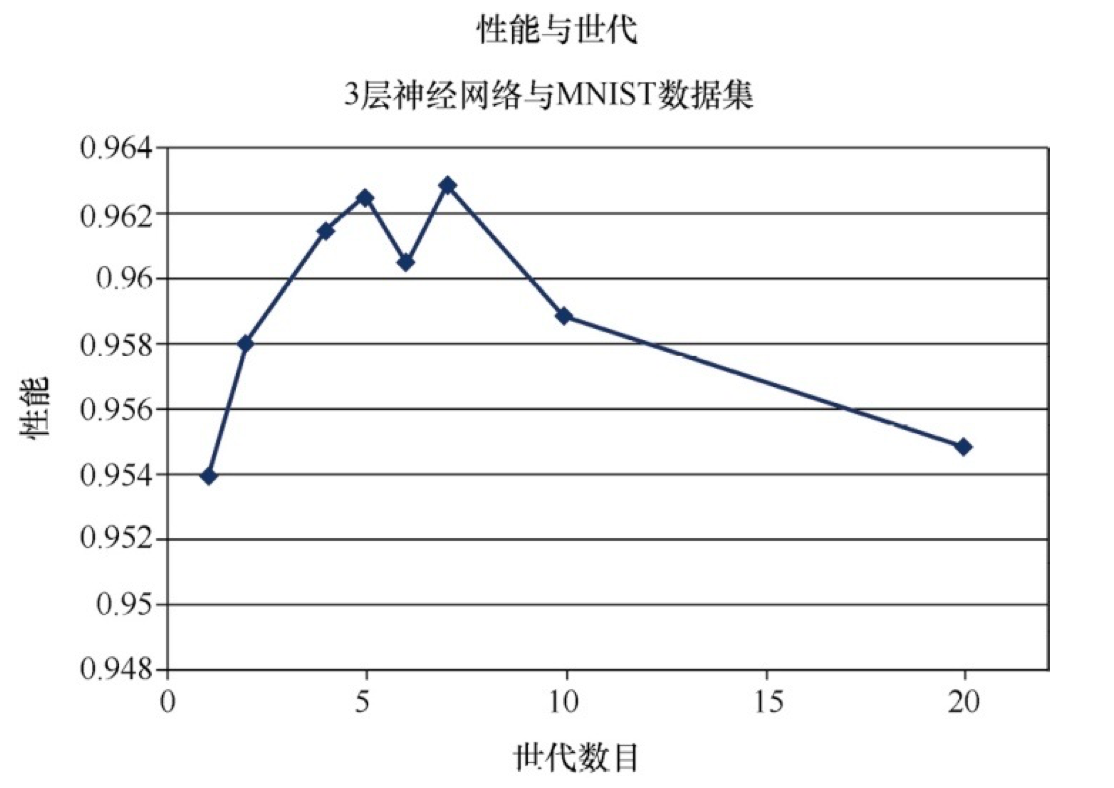
如上图所示,在大约5或7个世代时,有一个甜蜜点。在此之后,性能会下降,这可能是过度拟合的效果。性能在6个世代的情况下下降,这可能是运行中出了问题,导致网络在梯度下降过程中被卡在了一个局部的最小值中。
直观上,如果打算使用更长的时间(多个世代)探索梯度下降,那么你可以承受采用较短的步长(学习率),并且在总体上可以找到更好的路径,这是有道理的。要正确、科学地做到这一点,就必须为每个学习率和世代组合进行多次实验,尽量减少在梯度下降过程中随机性的影响。
改变网络形状
在这里我们主要去改变中间隐藏层节点的数目,因为输入节点只需引入输入信号,输出节点只要送出神经网络的答案,隐藏层是发生学习过程的层次。
如果隐藏层节点太少,比如说3个,那么你可以想象,这不可能有足够的空间让网络学习任何知识,并将所有输入转换为正确的输出。
如果有10000个隐藏层节点,会发生什么情况呢?虽然我们不会缺少 学习容量,但是由于目前有太多的路径供学习选择,因此可能难以训练网络。这也许需要使用10000个世代来训练这样的网络。
趣味盎然
神经网络的工作方式是将学习分布到不同的链接权重中。这种方式使得神经网络对损坏具有了弹性,这就像是生物大脑的运行方式。删除一个节点甚至相当多的节点,都不太可能彻底破坏神经网络良好的工作能力。
向后查询?
馈送一个标签到输出节点,通过已受训练的网络反向输入信号,直到输入节点弹出一个图像。下图是对神经网络反向输入数组 [0.99, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01,0.01] (即代表数字0的输出)后的结果:
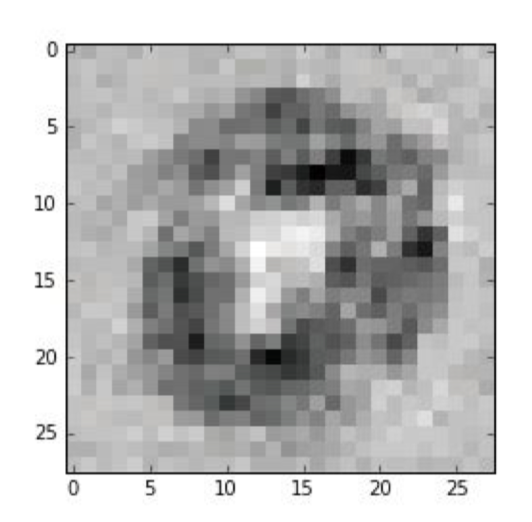
可见:如何将图像归类为标 签“0”,神经网络已经学习到的知识。