大概是在2020年年初的时候,微信上线了「微信圈子」这个功能,产品和「知识星球」比较像,我第一时间注册了「性能优化」这个圈子,疫情期间也发表了几十个动态,后面由于工作太忙也就没有精力去维护了。2021年5月28日,微信圈子发布公告表示,因业务发展方向调整,将于2021年12月28日正式停运。
我当时的圈子介绍(匿了):
提供新鲜、扎实的性能优化技巧,分享一线性能案例及调优经验,致力于构建最丰富、最有含金量的软件调优知识体系。
好吧,好在数据能导出,基于「微信圈子」里的内容,就有了这篇「性能优化随想录」,这篇文章会记录一些性能调优中的一些 tips,同时也缅怀一下我创建的的第一个知识社区。
方法论
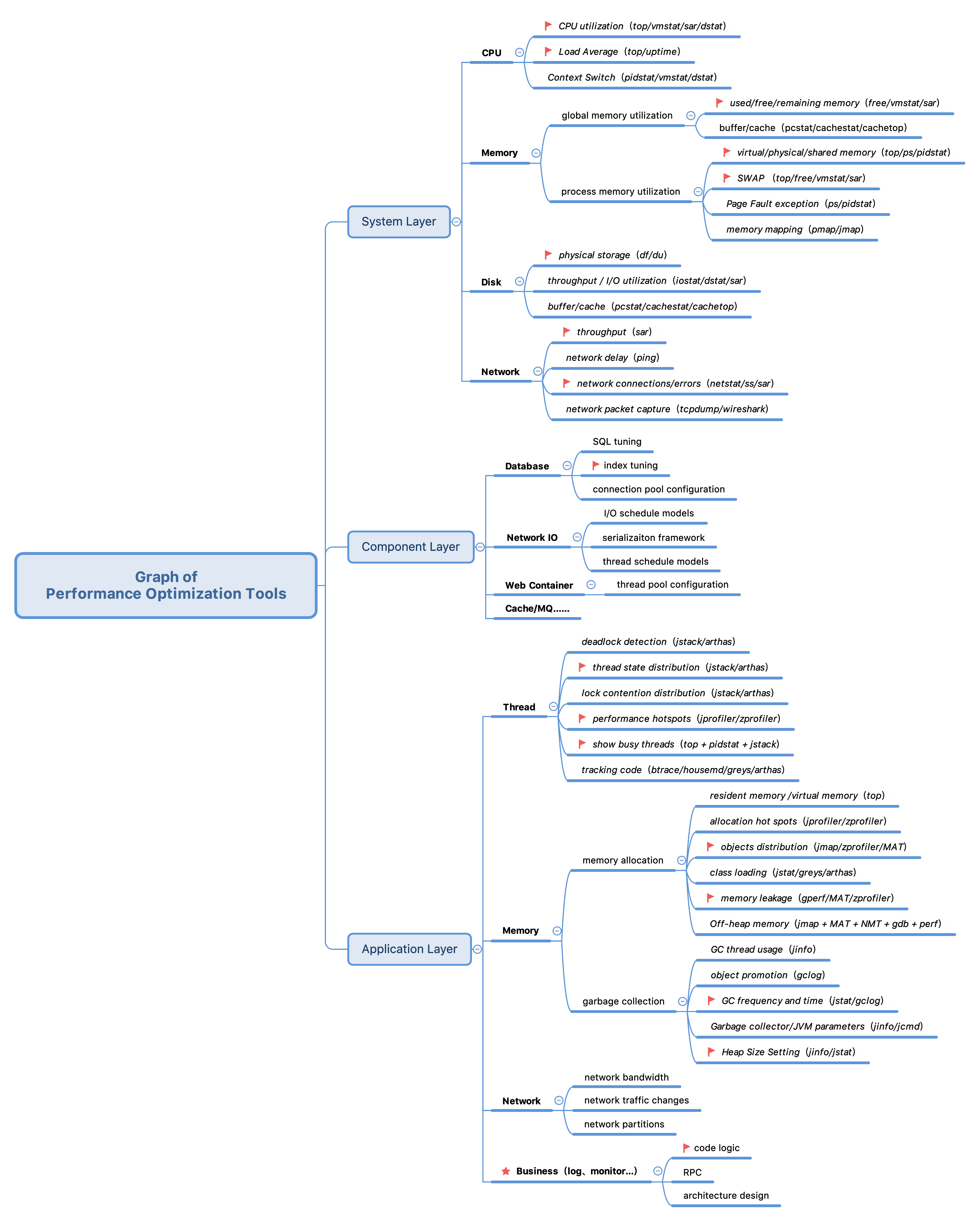
1、压轴神器:性能优化工具图谱。
2、Github上的 async-profiler 项目是一个可以对 Java 应用进行profiling 的工具,可以很方便生成火药图,是剖析 CPU 性能瓶颈的利器。
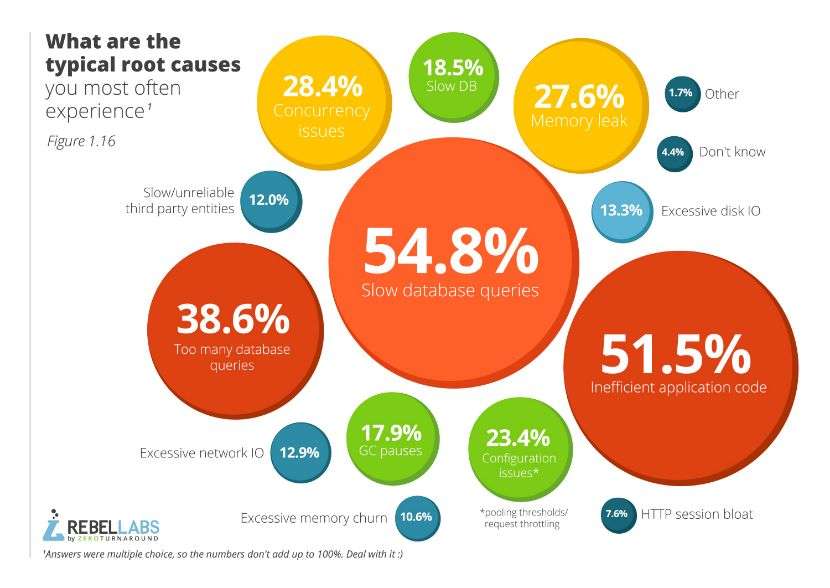
3、日常工作中遇到的性能问题中,因为数据库慢查询占54.8% ,不高效的代码占到 51.5% ,而我们经常提到的 GC 问题只占 17.9%,IO 问题也只占 13% 。通过此图告诉我们在分析问题的时候一定要避免盲目,通过一些排查方法来帮助我们找到问题的根本原因,这会让我们的优化事半功倍。
JVM
1、JVM 中如果要触发一次GC,那么 JVM 里的所有Java 线程都必须到达 GC safepoint,因为 JVM GC需要知道在发生 GC 的时刻,调用栈、寄存器等一些重要的数据区域里包含的GC管理的指针信息。线程是如何知道遇到 GC safepoint 就停下来呢?实际上,JVM 是把特定的某一页内存置为了不可读的状态,线程经过 GC safepoint 时,会获得一个 SEGV 信号。
2、在 JVM 启动参数的GC参数里,多加一句:-XX:+PrintGCApplicationStoppedTime,就可以把JVM的停顿时间(不只是GC),打印在GC日志里。
3、JVM 堆内存溢出后,其他线程是否可继续工作?答案是还能运行。发生 OOM 的线程一般情况下会死亡,也就是会被终结掉,该线程持有的对象占用的 Heap 都会被 GC 了,释放内存。因为发生 OOM 之前要进行 GC,就算其他线程能够正常工作,也会因为频繁 GC 产生较大的影响。
4、通过 NMT,我们可以观察细粒度内存使用情况,设置 -XX:NativeMemoryTracking=summary/detail 可以开启 NMT 功能,开启后可以使用 jcmd 工具查看 NMT 数据:jcmd pid VM.native_memory summary。
5、在启动程序时设置 JVM 参数 -XX:+PrintStringTableStatistic,程序退出时可以打印出字符串常量表的统计信息。
数据库
1、MySQL 中,什么样的列必须要创建索引呢?答:当一个列出现在 where 条件中,该列没有创建索引并且选择性(不重复的值的个数/总个数)大于 20% 时,那么该列必须创建索引,从而提升 SQL 查询性能,当然,如果本身表就很小,就更没必要建索引了?
2、哪些列适合适合加索引:经常检索的列,经常用于表连接的列,经常排序 / 分组的列。不应该加索引的列:基数很低的列,比如男女、订单状态等,更新频繁检索不频繁的列,blob/text 等长内容的列,很少用于检索的列。
3、阿姆达尔(Amdahl)定律:对系统中某一部件采用更快执行方式所能获得的系统性能改进程度,取决于这种执行方式被使用的频率,或所占总执行时间的比例。阿姆达尔定律实际上定义了采取增强(加速)某部分功能处理的措施后可获得的性能改进或执行时间的加速比,即加速比 = 优化前系统耗时/优化后系统耗时。
4、在设计数据库 Schema 的时候,尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
5、当查询 MySQL 数据时,当明确只要一行数据时,请使用 Limit 1。当查询表已经知道结果只会有一条结果,在这种情况下,加上 Limit 1 可以增加性能。MySQ L数据库引擎会在找到一条数据后停止搜索,而不是继续往后查少下一条符合记录的数据。
6、并不是所有索引对查询都有效,SQL 是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL 查询可能不会去利用索引,如一表中有字段 sex,male、female 几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
7、索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。一旦创建了多字段的联合索引,我们要考虑尽可能利用索引本身完成数据查询,减少回表的成本。
8、Spring 中如果方法涉及多次数据库操作,并希望将它们作为独立的事务进行提交或回滚,那么我们需要考虑进一步细化配置事务传播方式,也就是 @Transactional 注解的 Propagation 属性。
9、每一个存储系统都有其独特的数据结构,数据结构的设计就决定了其擅长和不擅长的场景。MySQL InnoDB 引擎的 B+ 树对排序和范围查询友好,频繁数据更新的代价不是太大,因此适合 OLTP(On-Line Transaction Processing)。ES 的 Lucene 采用了 FST(Finite State Transducer)索引 + 倒排索引,空间效率高,适合对变动不频繁的数据做索引,实现全文搜索。InfluxDB 对于时间序列数据的聚合效率远远高于 MySQL,但因为没有主键,所以不是一个通用数据库。Redis 对单条数据的读取性能远远高于 MySQL,但不适合进行范围搜索。
10、当数据库中的数据有更新的时候,需要考虑如何确保缓存中数据的一致性。我们看到,「先更新数据库再删除缓存,访问的时候按需加载数据到缓存」的策略是最为妥当的,并且要尽量设置合适的缓存过期时间,这样即便真的发生不一致,也可以在缓存过期后数据得到及时同步。
网络优化
1、TCP 三次握手建立连接需要的时间非常短,通常在毫秒级最多到秒级,不可能需要十几秒甚至几十秒。如果很久都无法建连,很可能是网络或防火墙配置的问题。这种情况下,如果几秒连接不上,那么可能永远也连接不上。因此,设置特别长的连接超时意义不大,将其配置得短一些(比如 1~5 秒)即可。如果是纯内网调用的话,这个参数可以设置得更短,在下游服务离线无法连接的时候,可以快速失败。
存储设计
todo
代码优化
1、众所周知,Java 的 Hashmap 是线程不安全的,那具体是哪些地方不安全呢?在 JDK1.7 中,在多线程环境下,扩容时会造成环形链或数据丢失。在JDK 1.8中,在多线程环境下,会发生数据覆盖的情况。
2、对于插入操作,LinkedList 的时间复杂度其实也是 O(n)。继续做更多实验的话你会发现,在各种常用场景下,LinkedList 几乎都不能在性能上胜出 ArrayList。讽刺的是,LinkedList 的作者约书亚 · 布洛克(Josh Bloch),在其推特上回复别人时说,虽然 LinkedList 是我写的但我从来不用……
3、Arrays.asList 得到的是 Arrays 的内部类 ArrayList,List.subList 得到的是 ArrayList 的内部类 SubList,不能把这两个内部类转换为 ArrayList 使用。Arrays.asList 返回的 List 不支持增删操作,不能直接使用 Arrays.asList 来转换基本类型数组,即数组应定义为 Integer[] arr2 = {1, 2, 3} 而不是 int[] arr1 = {1, 2, 3}。
4、如果一定要用 Double 来初始化 BigDecimal 的话,可以使用 BigDecimal.valueOf 方法,这也是官方文档更推荐的方式。浮点数的字符串格式化要通过 BigDecimal 进行,通过 DecimalFormat 来精确控制舍入方式,double 和 float 的问题也可能产生意想不到的结果。
5、Java 线程池是先用工作队列来存放来不及处理的任务,满了之后再扩容线程池。当我们的工作队列设置得很大时,最大线程数这个参数显得没有意义,因为队列很难满,或者到满的时候再去扩容线程池已经于事无补了。解决方案:a、可以重写队列的 offer 方法,造成这个队列已满的假象;b、实现一个自定义的拒绝策略处理程序,在达到了最大线程后再把任务真正插入队列。Tomcat 线程池也实现了类似的效果。
6、Java 线程池声明完后,可以立即调用 prestartAllCoreThreads 方法,来启动所有核心线程,避免因为创建核心线程来不及处理任务。
7、Java 异常处理中,可以把 try 中的异常作为主异常抛出,使用 addSuppressed 方法把 finally 中的异常附加到主异常上。
8、日志框架提供的参数化日志记录方式(使用{}占位符语法)不能完全取代日志级别的判断。如果你的日志量很大,获取日志参数代价也很大,就要进行相应日志级别的判断,避免不记录日志也要花费时间获取日志参数的问题。
9、对于反序列化默认情况下,框架调用的是无参构造方法,如果要调用自定义的有参构造方法,那么需要告知框架如何调用。更合理的方式是,对于需要序列化的 POJO 考虑尽量不要自定义构造方法。枚举不建议定义在 DTO 中跨服务传输,因为会有版本问题,并且涉及序列化反序列化时会很复杂,容易出错。因此,只建议在程序内部使用枚举。
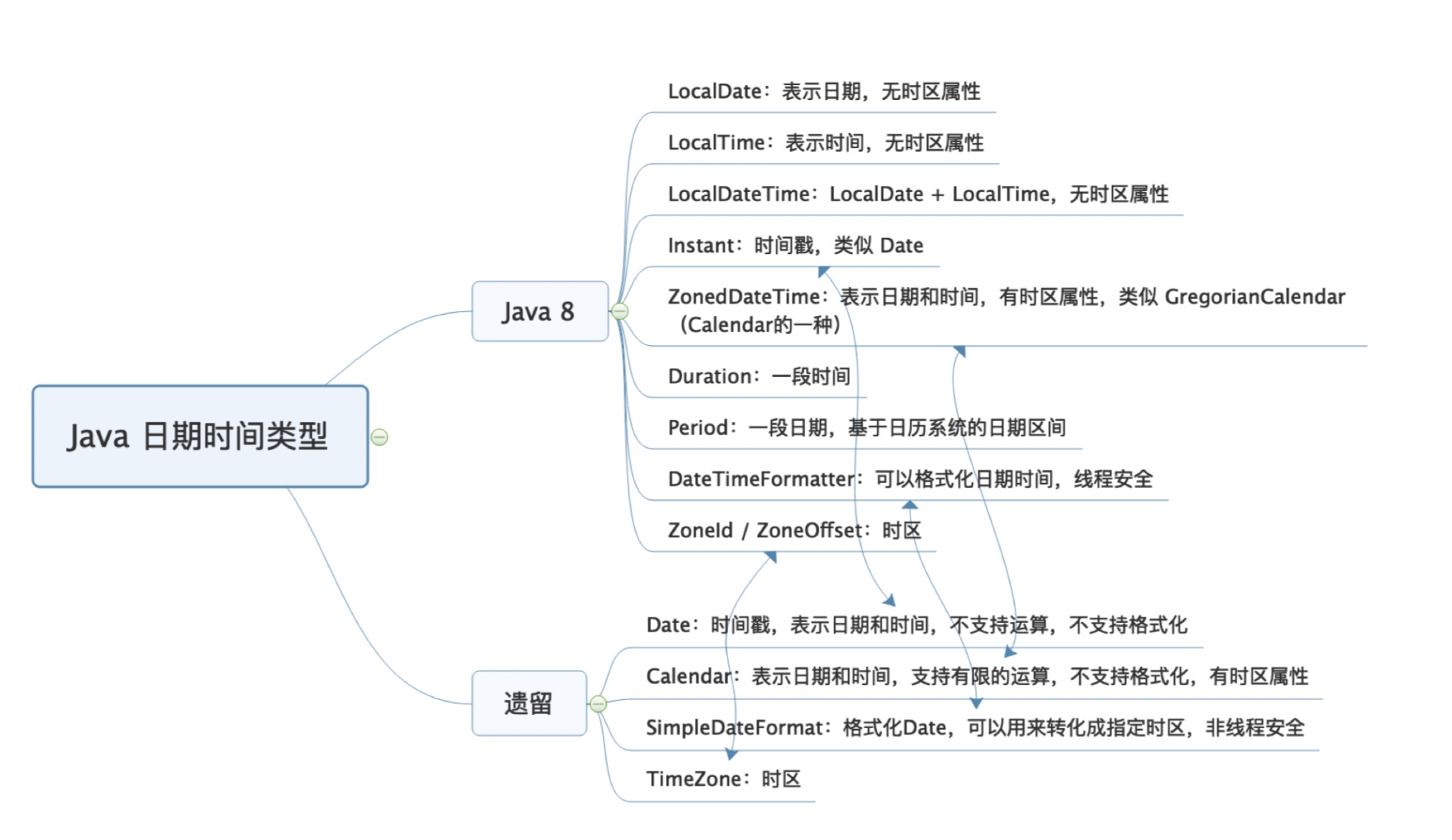
10、建议全面改为使用 Java 8 的日期时间类型,图中箭头代表的是新老类型在概念上等价的类型。
11、用户密码不能加密保存,更不能明文保存,需要使用全球唯一的、具有一定长度的、随机的盐(e.g. UUID),配合单向散列算法保存。盐的作用是,防止通过彩虹表快速实现密码「解密」,如果用户的盐都是唯一的,那么生成一次彩虹表只可能拿到一个用户的密码,这样黑客的动力会小很多。更好的做法是,不要使用像 MD5 这样快速的摘要算法,而是使用慢一点的算法,如 BCrypt 算法。诸如姓名和身份证这种需要可逆解密查询的敏感信息,需要使用对称加密算法保存,对称加密需要用到的密钥和初始化向量,可以和业务数据库分开保存。
12、性能好的代码,可以用四个字来概括:「多快好省」。「多」,吞吐量大;「快」,服务延迟低;「好」,扩展性好;「省」,资源使用量低(也即是资源使用效率高)。
13、串联的服务模块中,如果调用服下游务出现异常,应该采用指数退避机制(Exponential Backoff ),通过快速地降低对下游模块的请求速度,来帮助下游模块恢复(上游模块对下游资源进行重试请求的时间间隔,要随着失败次数的增加而指数加长)。